Figure 1:1 Corpus of the Survey of English Usage.
From Jan Svartvik (ed), The London Corpus of Spoken English: Description and Research. Lund Studies in English 82. Lund University Press, 1990.
As the name implies, the London-Lund Corpus of Spoken English (LLC) derives from two projects. The first is the Survey of English Usage (SEU) at University College London, launched in 1959 by Randolph Quirk, who was succeeded as Director in 1983 by Sidney Greenbaum. The second project is the Survey of Spoken English (SSE), which was started by Jan Svartvik at Lund University in 1975 as a sister project of the London Survey.
The goal of the Survey of English Usage is to provide the resources for accurate descriptions of die grammar of adult educated speakers of English. For that purpose the major activity of the Survey has been the assembly and analysis of a corpus comprising samples of different types of spoken and written British English. The original target for the corpus of one million words has now been reached, and the corpus is therefore complete.
The Survey has also engaged in devising and conducting elicitation experiments that are primarily intended to supplement data from the corpus. These experiments have focused on features in divided or rare use or whose grammatical status is in question. Such research has been particularly valuable in producing evidence for variation in usage and judgment among native speakers of English. This field of Survey activity, however, will not concern us here (see further Greenbaum 1988: 83-93).
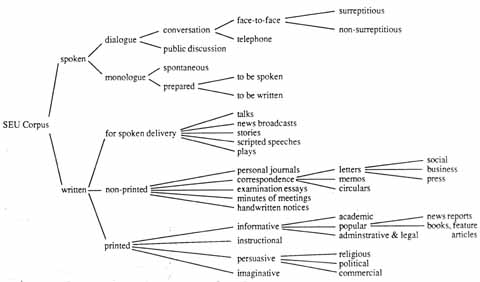
The SEU corpus contains 200 samples or 'texts', each consisting of 5000 words, for a total of one million words. The texts were collected over the last 30 years, half taken from spoken English and half from written English. The spoken English texts comprise both dialogue and monologue. The written English texts include not only printed and manuscript material but also examples of English read aloud, as in broadcast news and scripted speeches. The range of varieties assembled in the whole corpus is displayed in Figure 1:1.
Figure 1:1 Corpus of the Survey of English Usage.
In this book we are interested in the spoken half of the corpus. As can be seen in the figure, the major distinction is between dialogue and monologue. Within dialogue we distinguish conversation in private from public discussion. The most common type of conversation is face-to-face, which occurs when the participants can see each other and can observe each other's reactions. Technology allows for private conversation by telephone when the participants are not in the same place. 'Public discussion' is dialogue that is heard by an audience that does not participate in the dialogue; it includes interviews and panel discussions that have been broadcast. All the telephone conversations and many of the face-to-face conversations were recorded surreptitiously, which means that (at the time of recording) one or more of the participants did not know that their conversation was being preserved. These surreptitiously recorded conversations represent spoken English at its most natural. All the surreptitiously recorded face-to-face conversations with one exception (S.3.7, recorded in 1984) have been published in Svartvik & Quirk (1980).
Within monologue we distinguish spontaneous from prepared. Spontaneous monologue, which is nearest to conversation in being relatively unplanned, includes running commentaries on sport events and state occasions, demonstrations of experiments, and speeches in parliamentary debates. Prepared monologue, on the other hand, is closest to written English but retains some spontancity in not being read from a script and therefore allowing for improvisation. Typical prepared monologues in the corpus are sermons, lectures, addresses by lawyers and a judge in court, and political speeches. A special type of prepared monologue is represented by the text of dictated letters, where the speech is intended to be written down.
The spoken corpus of the Survey of English Usage has been transcribed with a sophisticated marking of prosodic and paralinguistic features. All the SEU texts, written as well as spoken, have been analysed grammatically. The grammatical analysis and the prosodic/paralinguistic analysis are represented in the Survey files by typed slips (6x4 inches). Each slip contains 17 lines, including 4 lines of overlap between that slip and the adjacent ones before and after. For each grammatical, prosodic and paralinguistic feature there is one slip that is marked for that item. The Survey collects 65 grammatical features, over 400 specified words or phrases, and about 100 prosodic and paralinguistic features.
In 1975 the Survey of Spoken English was established at Lund. lts initial aim was to make available, in machine-readable form, the spoken material which by then had been collected and transcribed in London: 87 texts totalling sorne 435 000 words (sce Svartvik et al 1982 for an account of the input procedures). The material was inserted in a reduced transcription and without grammatical analysis. Early in 1980 the first copies of the computerized London-Lund Corpus of Spoken English were distributed to interested scholars all over the world,
This original London-Lund Corpus of 87 texts (often referred to as LLC) has since been augmented by the remaining 13 spoken texts of the SEU corpus, which were processed at the Survey of English Usage in conforinity with the system used in the original London-Lund Corpus. These 13 texts constitute a supplement (LLC:s) to the original computerized version. The complete London-Lund corpus (LLC:c) therefore consists of 100 spoken texts. In addition, all the written texts of the SEU corpus are now computerized, but these do not form part of the London-Lund Corpus and will not be distributed, though they can be consulted at the Survey of English Usage at University College London. Since LLC has been widely used in scholarly publications for the last decade, it is important to distinguish in future publications the original version from the supplement and from the complete version that incorporates the supplement. In order to avoid misunderstanding we recommend using suffixes for all three thus:
LLC:o the original corpus (87 texts)
LLC:s the supplement (13 texts) to the original corpus
LLC:c the complete corpus (100 texts)
The constituents of the complete SEU corpus are displayed in Figure 1:2. Appendix I lists all the 100 spoken texts of LLC:c in order of text category, and provides (as far as the information is available) the dates of recordings and certain bibliographical details about the speakers.
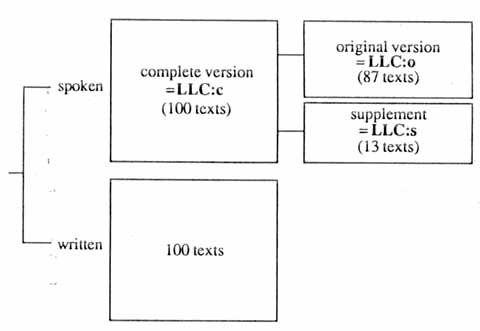
Figure 1:2 The computerized SEU corpus.
Within the written SEU corpus, 17 texts were recorded from spoken deliveries of written material, such as news broadcasts, plays, and scripted speeches. These are not included in LLC:c, though in the computerized version they have Leen transcribed in the same way as the spoken texts.
We must distinguish the full prosodic and paralinguistic transcription in the SEU corpus from the reduced transcription in LLC:c and in the computerized 17 texts that were read aloud from written material .
The basic prosodic features marked in the full transcription are tone unit boundaries, the location of the nucleus (ie the peak of greatest prominence in a tone unit), the direction of the nuclear tone, varying lengths of pauses, and varying degrees of stress. Other features comprise varying degrees of loudness and tempo (eg allegro, clipped, drawled), modifications in voice quality (pitch range, rhythmicality and tension), and paralinguistic features such as whisper and creak. Indications are given of overlap in the utterances of speakers. The full transcription and the grammatical analysis are available only on the slips at the Survey of English Usage at University College London.
The reduced transcription of the computerized LLC:c corpus and the 17 computerized texts of written English read aloud retains the basic prosodic features of the full transcription but omits all paralinguistic features and certain indications of pitch and stress. It retains the following features: tone units (including the subdivision where necessary into subordinate tone units), onsets (the first prominent syllable in a tone unit), location of nuclei, direction of nuclear tones (falls, rises, levels, fall-rises, etc), boosters (ie relative pitch levels), two degrees of pause (brief and unit pauses alone or in combination) and two degrees of stress (normal and heavy). Also indicated are speaker identity, simultaneous talk, contextual comment ('laughs', 'coughs', 'telephone rings', etc) and incomprehensible words (ie where it is uncertain what is said in the recording). For explanations of the prosodic and paralinguistic system we refer to Crystal 1969. Researchers may obtain from the Survey of English Usage a guide to the full SEU transcription and an account of differences between the full and the reduced transcriptions. Figure 1:3 presents a sample slip with the full transcription, and Figure 1:4 gives the same passage (tone units 139-163 of text S.1.3) in reduced transcription as printed in Svartvik & Quirk 1980:85.

Figure1:3.

Figure1:4.
There is a concordance of LLC:o, and both the text and the concordance are available from the International Computer Archive of Modern English (ICAME). We hope that die complete spoken corpus (LLC:c) will be available from ICAME in the near future.
The address of ICAME, where copies of the London-Lund Corpus can
be obtained, is:
The HIT Centre,
Allégt. 27,
N-5007 Bergen,
Norway
icame@hit.uib.no
The address of the Secretary of ICAME is:
Prof. Matti Rissanen
Department of English
P.O. Box 4 (Yliopistonkatu 3)
FI-00014 University of Helsinki
Finland
matti.rissanen@helsinki.fi
The address of the Editor of ICAME Journal is:
Merja Kytö
Department of English
University of Uppsala
P.O. Box 513
S-751 20 Uppsala
Sweden
merja.kyto@engelska.uu.se
The spoken texts in the full or reduced version have been extensively used by scholars throughout the world in studies of spoken English and in comparisons between the spoken and written language. For computer studies, comparisons have been drawn between the London-Lund Corpus and two corpora of printed texts dating from 1961, each consisting of about one million running words: the Lancaster-Oslo/Bergen (LOB) British corpus and the Brown University Arnerican corpus. Comparative studies generally refer to frequency differences within and across the corpora (see Chapter 2).
The Survey of English Usage holds a list of publications that have
used Survey material, including LLC, and updates the list annually.
The list is available to scholars on request. Appendix 2 shows that
well over 200 publications have used Survey material, and no doubt
there are more that are not known to us. They consist of general
works (such as grammars), monographs, chapters in books, and
articles. Prominent among the books is the standard reference grammar
of modem English - A comprehensive grammar of the English language
(Quirk et al 1985).
APPENDIX 1
The complete London-Lund Corpus
Below we provide basic information on all the 100 spoken texts (ie the complete version of the London-Lund Corpus, above referred to as 'LLC:c'), including text category (eg conversation), year of recording (eg 1984), speaker category (eg female undergraduate) and speaker age (eg c. 20). In this complete listing, the 87 texts included in the original London-Lund Corpus are marked 'LLC:o'; the 13 texts which constitute a supplement are marked 'LLC:s'; the 34 texts available in print (Svartvik & Quirk 1980) are marked 'CEC'.
Unless indicated otherwise, the speakers are British. In the recordings made without prior knowledge of the main participants, the narnes used in the transcriptions are fictitious but prosodically equivalent to the originals. Speakers denoted by upper case letters have been surreptitiously recorded. Sometimes one or more participants had knowledge of the recording (and had the task of keeping the conversation going); such speakers, whose contributions have not been prosodically transcribed, have been specially designated by lower case letters. Some of the texts are comPosite and contain 'subtexts', either with the same speakers, or recorded in a comparable setting.
SURVEY OF SPOKEN ENGLISH
Director: Jan Svartvik, Lund University, Department of English, Helgonabacken 14, S-223 62 Lund, Sweden
The London-Lund Corpus of Spoken English
(Information to accompany the CD-ROM)
This material is the property of the Survey of English Usage,
University College London, and is made available to specialist
scholars for the purposes solely of scientific research and must not
be distributed or reproduced, wholly or in part, for any other
purpose.
The corpus consists of 100 texts, each of 5000 words, totalling
500.000 running words of spoken British English. Information about
the compilation of the corpus and explanation of the symbols
(prosodic, phonetic, etc.) used on the CD-ROM can be found in the
printed volume A Corpus of English Conversation, edited by J.
Svartvik & R. Quirk, Lund Studies in English 56,
Lund: Liber/Gleerups, 893 pp, (1980).
Description of Records in an SSE Text
|
|
|
Contents |
|
1-2 |
I2
|
Text category |
(1): Records make up complete or incomplete TUs. A complete TU is terminated by '#' (number sign). Following '#' there may also be pauses, comments, or semicolons. Semicolon (decimal code 59) is used to denote a blank.
Speakers often interrupt each other and, consequently, TUs may be split up into so-called links. TU links may be interwoven. For a TU to be considered properly linked, all links except possibly the last one must be incomplete, i.e. it lacks '#', and the speaker should be indicated by '(' in col 18 in all links except possibly the first one. Study TUs 16-17 in text 1-1!
Every TU consists of at least one link. If there are more, links are numbered in decreasing order (cols 14-15).
A link normally goes into one record ('line') but may extend over several. Within each link, therefore, lines have been numbered, in decreasing order.
|
|
S |
D |
F |
P |
S |
R |
|
SUB |
TEXT |
|
|
ABBRE- |
BROAD |
|||||||||
|
CON |
Face-to-face |
A |
+ |
+ |
+ |
+ |
- |
S.1.-14, S.2.1-14, S.3.1-6 |
34 |
46 |
|
TEL |
Telephone |
C |
+ |
- |
+ |
+ |
- |
S.7.1-3, S.8.1-4, S.9.1-32 |
10 |
10 |
|
DIS |
Discussion, |
D |
+ |
+ |
- |
- |
+ |
S.5.1-7, S.6.1, S.6.3-53, S.10.84 |
12 |
12 |
|
PUB |
Public, unprepared commentary, |
E |
+ |
+ |
- |
- |
- |
S.11.1, S.11.4-5 |
3 |
12 |
|
PRE |
Public, prepared oration |
H |
- |
+ |
- |
- |
- |
S.11.2, S.12.1-67 |
7 |
7 |
|
Number of "+" texts: |
||||||||||
|
71 |
70 |
56 |
44 |
21 |
87 |
87 |
||||
NOTES
1. Subgroup B is composite; individual speakers can be marked for surreptitiousness
2. S.9.3 is ansaphone calls
3. Subtext S.6.4b, which constitutes only a minor part of Text S.6.4, is not a radio recording but a discussion between an ex-nurse and a research worker on a topic similar to that of S.6.4a.
4. Subtext S.10.8b is not a radio recording. It has been placed in S.10.8 because it is very short, less than 100 tone units. Furthermore, the speaker in S.10.8b is one of the speakers in S.10.8a and both subtexts deal with popular science.
5. S.6.6 is an interview which, as it turned out, virtually became a monologue.
6. Subtext S.10.6a is a TV recording. Subtext S.10.7c is not a radio recording (like the main part of Text S.10.7) but a demonstration.
7. There are two speakers in S.12.3. However, it has been placed in this group since it is virtually a monologue.
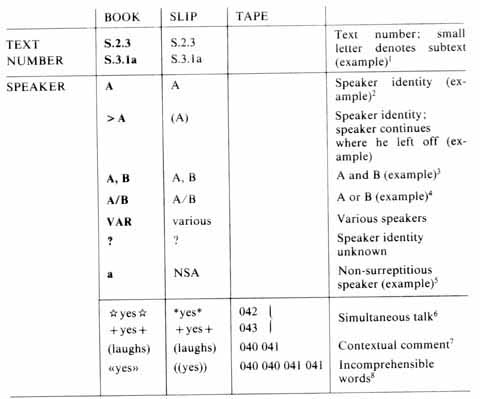
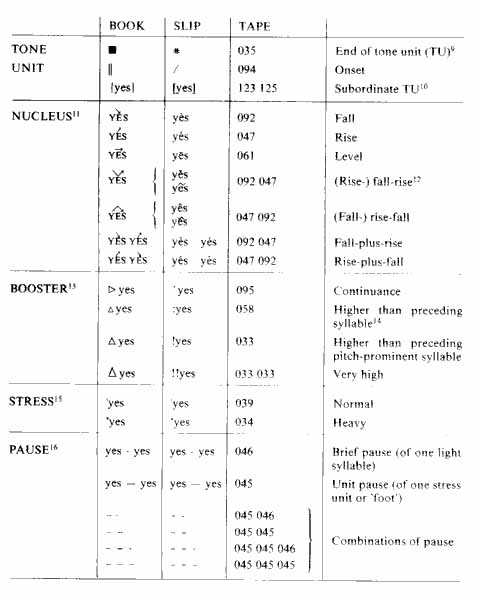
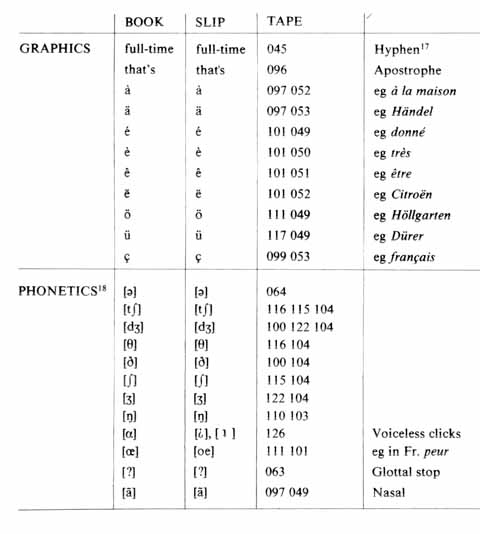
List of symbols
The following section lists the symbols used in the transcription. The material now exits in three different versions: on paper slips in the Survey of English Usage, University College London and the Survey of Spoken English, University of Lund (SLIP); on CD-ROM (TAPE); and in the printed form of this book (BOOK). Since some users of this corpus may want to use or refer to more than one version, the symbols used in three versions have been listed below, side by side. It is not possible to explain the symbols here and for explanations of the prosodic system we refer to Quirk et al 1972 (Appendix II), Crystal 1969 and Crystal and Davy 1975.